How to set up data transferring folder in Windows (updated: 2024-05-02 12:20:10)
Set up the IDUN folders(Easy way)
The IDUN folder is a network drive. You can access it through NTNU VPN or NTNU network. There are two samba servers idun-samba1,idun-samba2.
The setting up of Network Drive is following the steps:
1. Open the file explorer– This PC
2. Click on the Computer tab, then click on the Map network drive button.
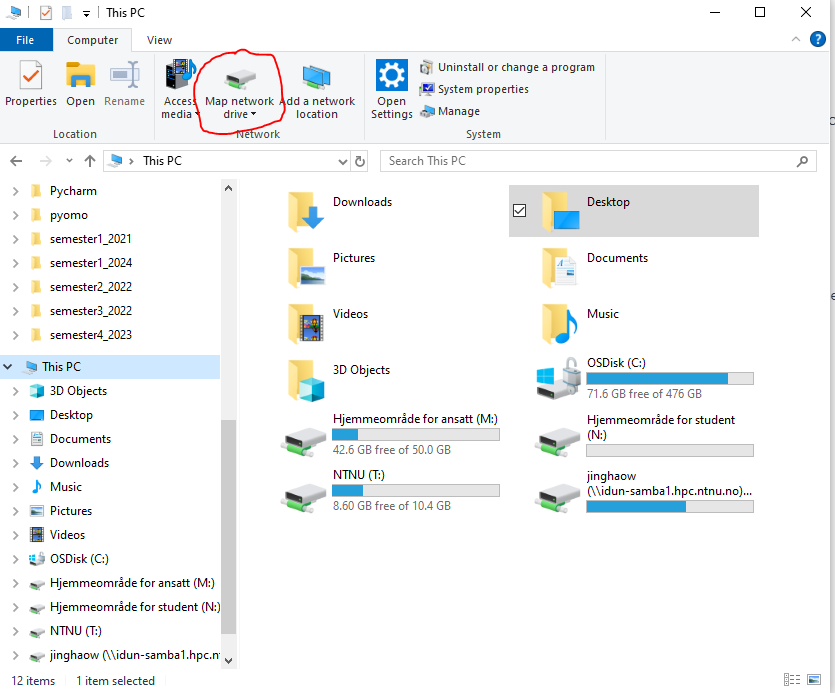
3. Enter the remote folder address: \\idun-samba1.hpc.ntnu.no<username> (username is your NTNU feide username)
- remember to check the box of ‘Connect using different credentials’
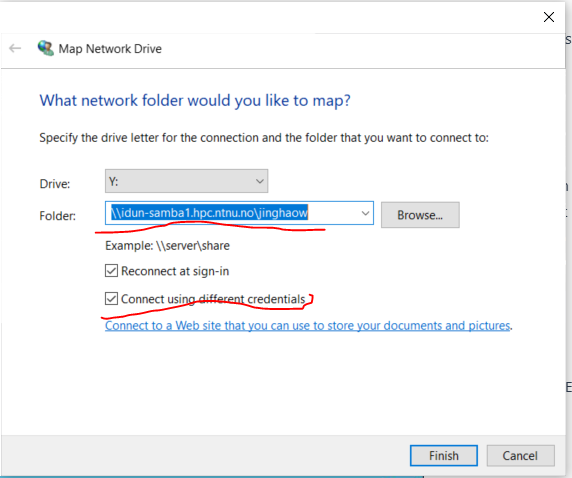
4. Enter your usernames need to be entered in this form: WIN-NTNU-NO<username>
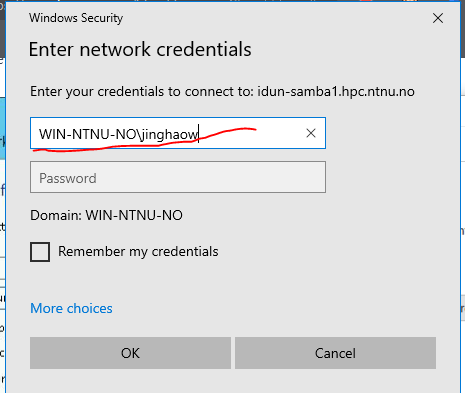
5. Click OK, and you will be prompted to enter your password.
For detailed information and non-windows setting, please refer to the IDUN page:
Server Login by SSH using PuTTY (seldom used)
1. Set up server and login
You can log into IDUN through launching PuTTY. This is already installed on the server. The approach for this is well described in:
When launching PuTTY, you can access IDUN through filling in the fields as follows:
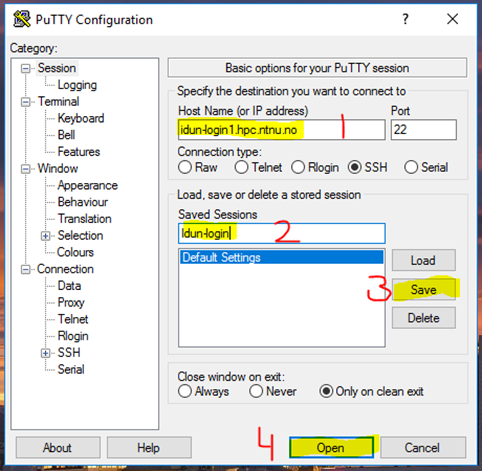
2. Log in with your NTNU username and password: (The password will not show in the window)
The IDUN cluster has two login nodes:
idun-login1.hpc.ntnu.no
idun-login2.hpc.ntnu.no
This ssh part will show in the cmd window
2. Apply for a working space
Easy command: interactive
salloc --account=share-ie-iel --nodes=1 --cpus-per-task=16 --time=01:00:00 --constraint="pec6520&56c"
- ==salloc== :Option(s) define multiple jobs in a co-scheduled
- ==account== : here is just you are using iel account
- == node== : related to parallel process, if no modification on the
- ==cpus-per-task== : cpu-cores per task >1 if multi-threaded tasks
- ==time== : total run time limit (DD-HH:MM:SS)
- ==constraint== : force which type component should use
To check the list, using:
sinfo -a -o "%22N %8c %10m %30f %10G "
After this step, the location and node will be assigned, like idun-xx-xx
Then
ssh idun-xx-xx
3. From Ondemand to resource reservation
The Ondemand is a new interface for the IDUN, which is easier to use. The link is:
1. Loging in Clusters
3. install packages
module load Anaconda3/2022.10 <Load anaconda>
conda create -n <env_name> python=3.8 --channel conda-forge --override-channels --yes
-Create a conda “environment” with python 3.8, env_name == name : e.g. conda create –name tf2-gpu python=3.8
conda activate
Once the env set, don’t need to install again. Everytime when you start something, remember to use:
module load Anaconda3/2022.10
4. Gurobi installation
Add channel for the installation of the gurobi:
conda config --show channels
conda config --add channels https://conda.anaconda.org/gurobi #(https://conda.anaconda.org/gurobi could be spicified by any channel you want to add)
conda config --show channels
Installer gurobi-suits for python:
conda install gurobi=9 --yes
Add the channel conda-forge for the rest of the installation:
conda config --env --add channels conda-forge
conda config --env --set channel_priority strict
conda config --env --get channels
for pyomo, there are some requirement on installed package
conda install openpyxl
conda install -c conda-forge pyomo ## install pyomo
conda install -c conda-forge ipopt glpk ##install ipopt and glpk solver
** forge is a channel, better to install all the packages here
5. JUPYTER NOTEBOOK
ADD IPYTHON KERNEL
create the environment, activate it, and install the ipykernel:
conda create --name [env_name] python=[python version]]$
-To activate the conda environment :
conda activate [env]$
-Install ipykernel using:
conda install ipykernel
-Add ipykernel to the env list:
ipython kernel install --user --name=[name]
-Check kernel list :
$jupyter kernelspec list$
6. SLURM file for submitting sequential jobs–sbatch
The Sbatch usually is for running for sequential or parallel jobs. Or submission of the reservation for the resources.
The difference between the Sbatch submission and interactive is that the sbatch is that you can leave it in the system.
Interactive is for the real-time operation.
When saving the results, Sbatch needs a saving function of the results; otherwise it won’t save the results.
You can see the results in the interactive.
Example: Assume you have a python function called test.py, and you want to run it with sbatch.
python test.py:
for i in range(20):
print(i)
test.slurm should be like this:
#!/bin/bash
#SBATCH --account=share-ie-iel ## our account name
#SBATCH --time=0-1:00:00 ## time limit for the job 0 days, 1 hour, 0 minutes
#SBATCH --job-name=test ## job name
#SBATCH --output=hello.txt ## output file name if you want to add dircetory, use #SBATCH --output=/path/to/output/test.out
#SBATCH --nodes=1 ## number of nodes . This is for the parallel process most time is 1
#SBATCH --cpus-per-task=1 ## number of cpus per task, how many CPU's you want
#SBATCH --mem-per-cpu=1G ## memory you need
#SBATCH --constraint="pec6520&56c" ## constraint for the CPU type
#SBATCH --mail-user=your_email@example.com ## email address
source /cluster/apps/eb/software/Anaconda3/2022.10/etc/profile.d/conda.sh ## load the conda from the path
conda activate [env_name]
python test.py
when you run the sbatch, you need to submit the job by sbatch test.slurm.Then you can submit the job by sbatch test.slurm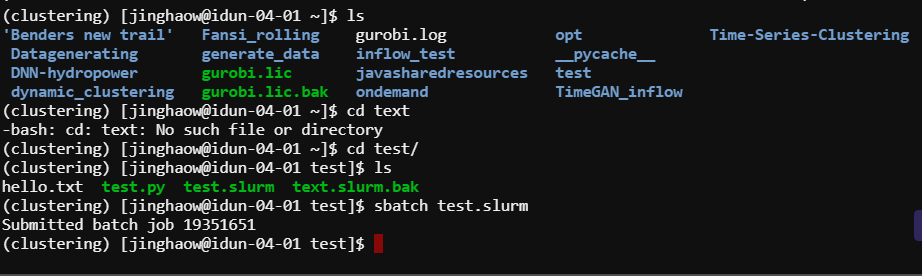
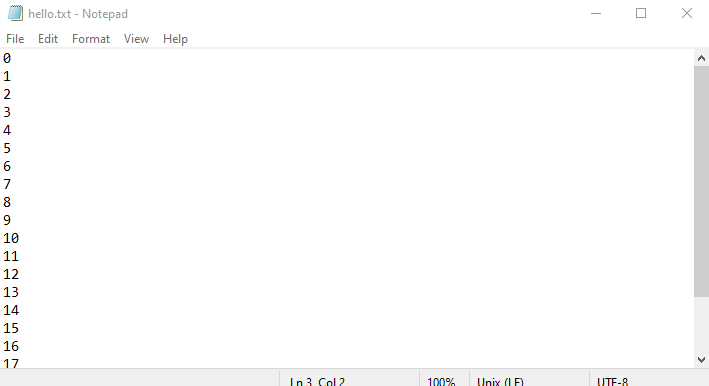
The results will be saved in the hello.out file, like this.
7. SLURM file for submitting parallel jobs–srun
Same as #6. The difference is that the srun is for the parallel process.
For example, we have a python function called test.py, and you want to run it with srun.
Inside the function, you want to run 10 parallel process.
## the function we have
def test(numb):
return numb
# the parallel process
def run_test(index): ## get 10 result based on the index
state_index = (index-1)*10
end_index = index*10
DATA = dict()
for a in range(state_index,end_index):
result= test(a)
DATA[a]=result
# if the index is 1, the result will be 0-9
# save the results
with open(r'output/'+'data_output'+str(index)+'.txt', 'w') as f:
f.write(str(DATA))
# now we creat a function to run the parallel process
if __name__ == '__main__':
import sys
index = int(sys.argv[1])
run_test(index)
The slurm file should be like this:
#!/bin/sh
#SBATCH --partition=CPUQ
#SBATCH --array=1-299 ## the number of parallel process for setting the index
#SBATCH --account=share-ie-iel
#SBATCH --time=04:00:0
#SBATCH --nodes=1
#SBATCH --cpus-per-task=16
#SBATCH --mem=32G
#SBATCH --job-name="LASTDANCE"
#SBATCH --output=./srun_out_2/%x.%a.%j-srun.out ## x is the job name, a is the array index, j is the job id
#SBATCH --mail-user=jinghao.wang@ntnu.no
#SBATCH --mail-type=ALL
The same process to submit to the job by srun test.slurm. The running log will be saved in the srun_out_2 folder.
The log file:
The outputfile:
There are some detailed information about how to use the IDUN, which is well documented in the IDUN page:
some helpful cmd
for personal use
list all the packages
conda list
remove packages
conda remove
check who is online
who
terminate currtent process
ctrl +D
exit
PATH setting doc
vim ./bashrc ## check bash
i # start insert
esc+:wq # save and quit
esc+:q # directly quit
PATH="...:$HOME/Fansi_rolling:..."
check resources
sinfo -a -o "%22N %8c %10m %30f %10G "
you can also find it here:https://www.hpc.ntnu.no/idun/
checking the CPU and GPU capacity
htop
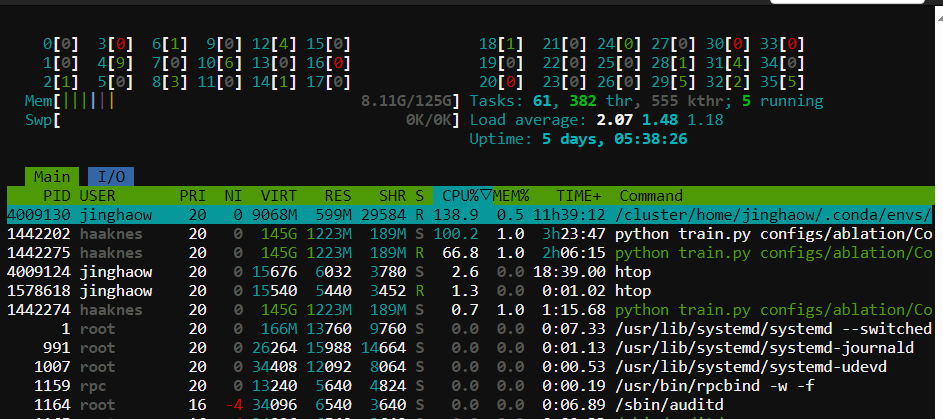
nvidia-smi
PyTorch on the HPC Clusters | Princeton Research Computing
The installation of Cplex solver is also available in the IDUN, which is in another blog.
Special Thanks to Runar Mellerud and Anders Gytri’s help on the IDUN documentation support.